27번
VIEW
- 독립성 : 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다.
- 편리성 : 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있다. 또한 해당 형태의 SQL문을 자주 사용할 때 뷰를 이용하면 편리하게 사용할 수 있다.
- 보안성 : 직원의 급여정보와 같이 숨기고 싶은 정보가 존재한다면 해당 칼럼을 빼고 생성함으로써 사용자에게 정보를 감출 수 있다.
28번
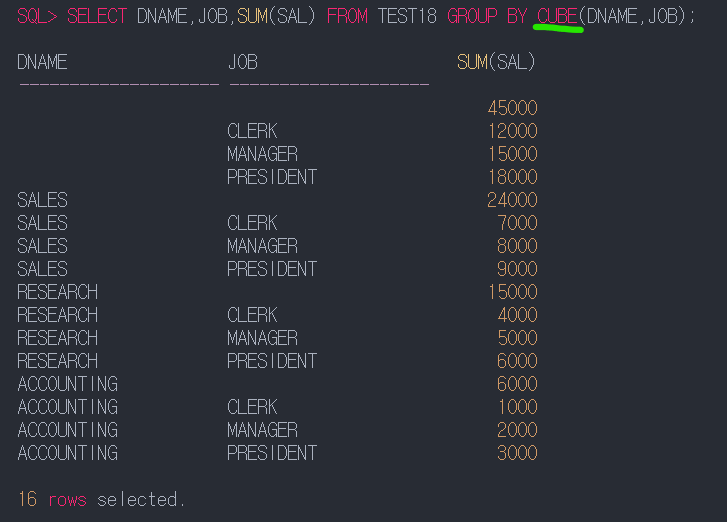
GROUP BY
GROUP BY구의 기본적인 문법을 확인하는 문제
SELECT구에는 GROUP BY절에 있는 칼럼이 나와야 한다.
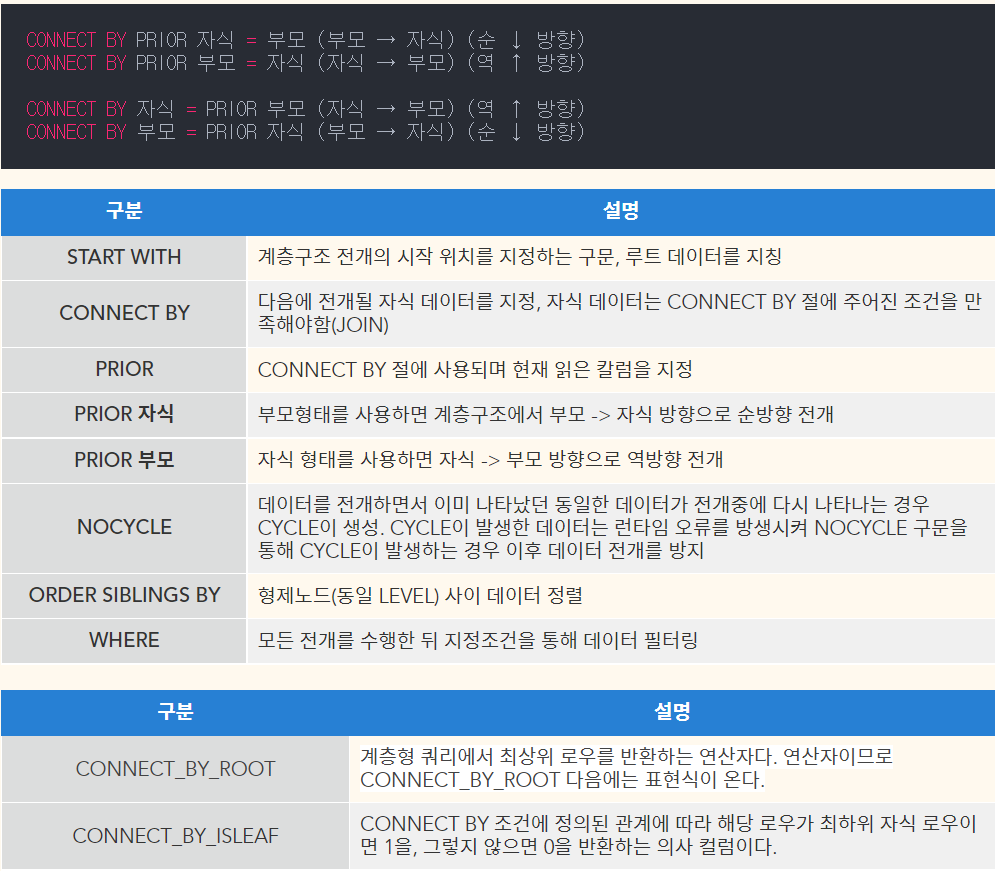
29번
교차엔터디(Intersaction Entity)
M:M의 관계를 해소하려는 목적으로 만들어진 엔터티 [ex> M:M -> 1:M]
독립 엔티티[Kernel Entity, Master Entity]
사람, 물건, 장소 등과 같이 현실세계에 존재하는 엔터티
업무중심 엔터티[Transaction Entity]
Transaction이 실행되면서 발생하는 엔터티
종속 엔터티[Dependent Entity]
주로 1차 정규화로 인해 관련 중심엔티티로부터 분리된 엔터티
교차 엔티티[Intersaction Entity]
M:M의 관계를 해소하려는 목적으로 만들어진 엔터티
ex> M:M -> 1:M
30번
CORRELATED SUB QUERY(상호연관 서브쿼리)
메인쿼리의 값을 서브쿼리에서 주입을 받아서 비교를 하는 것
메인쿼리의 값을 서브쿼리에서 주입을 받아서 비교를 하는것으로 상호연관 서브쿼리(CORRELATED SUB QUERY) 이다.
SELECT A.EMPNO, A.ENAME
FROM EMP A
WHERE A.EMPNO = (SELECT 1 FROM
EMP_T B WHERE A.EMPNO = B.EMPNO);
서브쿼리에 *(A.EMPNO 값을 매번 가져와서 대입을 해야하므로성능이 매우 좋지않다.)
36번
SUBKPI,MAINKPI
20,10을 각각 대입
0,30을 각각 대입
SUBKPI가 0인건 없고 20인건 있어서 20,10이 TRUE로 WHERE발동
37번
서브쿼리 설명
- 서브쿼리에서는 정렬을 수행하기 위해서 내부에 ORDER BY를 사용하지 못한다.
- 서브쿼리에 있는 칼럼을 자유롭게 사용할수 없다
- 여러 개의 행을 되돌리는 서브쿼리는 다중행 연산자를 사용해야 한다.
- EXIST는 TRUE와 FALSE만 되돌린다
38번
TO_DATE(), TO_CHAR()
TO_CHAR() : 날짜/숫자형 데이터를 문자형 데이터로 변경
TO_DATE() : 문자/숫자형 데이터를 날짜형 데이터로 변환
데이트(날ㅉ) 타입을 데이트타입으로 바꾸면 에러남. 그래서 1번 안됨
T0_DATE()로 ‘YYYYMMDD’ 형식 출력가능
39번
FETCH(읽어오기) 위해 해야할 것은
CURSOR OPEN (*CURSOR순서 : 선언 → OPEN → FETCH → CLOSE)
CURSOR(DB의 연결 포인트, 연결점)
- SQL 커서는 Oracle 서버에서 할당한 전용 메모리 영역에 대한 포인터이다.
- 질의의 결과로 얻어진 여러 행이 저장된 메모리상의 위치
- 커서는 SELECT 문의 결과 집합을 처리하는데 사용된다.
명시적 커서란
사용자가 직접 정의해서 사용하는 커서이고 묵시적(암시적) 커서는 데이터베이스가 내부적으로 사용하는 커서이다.
모든 CURSOR는 사용하기 전에 반드시 선언을 해주어야 한다

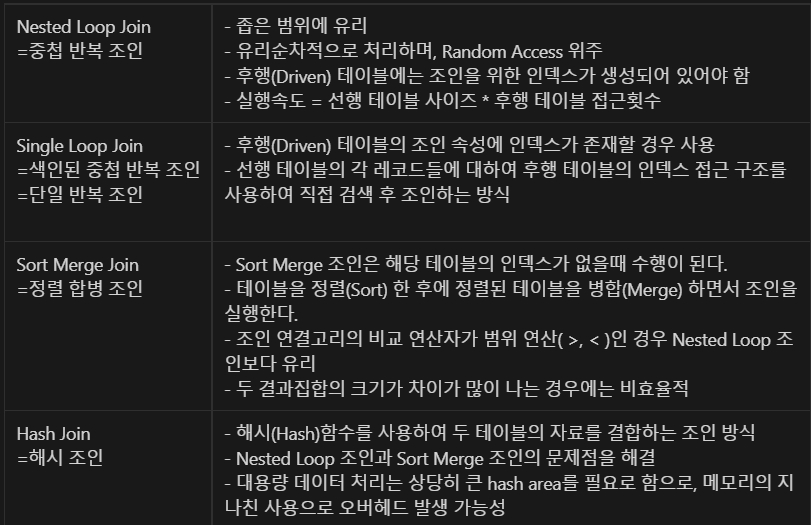
42번
NESTED LOOP JOIN
RANDOM ACCESS로 인해 부하가 걸림
HASH JOIN
- 조인 컬럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있다.
- 해시 함수를 이용하여 조인을 수행하기 때문에 '='로 수행하는 조인으로 동등 조건에만 사용가능
- 해시 함수가 적용될 때 동일한 값을 항상 같은 값으로 해싱됨이 보장된다.
- HASH JOIN 작업을 수행하기 위해 해시 테이블을 메모리에 생성해야 한다.
- 메모리에 적재할 수 있는 영역의 크기보다 커지면 임시 영역(디스크)에 해시 테이블을 저장한다.
- HASH JOIN을 할 때는 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.
- 선행 테이블을 Build input이라 하며, 후행 테이블을 Prove input이라 한다.
43번
2,3차 정규화
2차 정규화 → 3차 정규화(종속 존재를 분해) 학번,코스코드(FK),평가코드(FK) = 3개
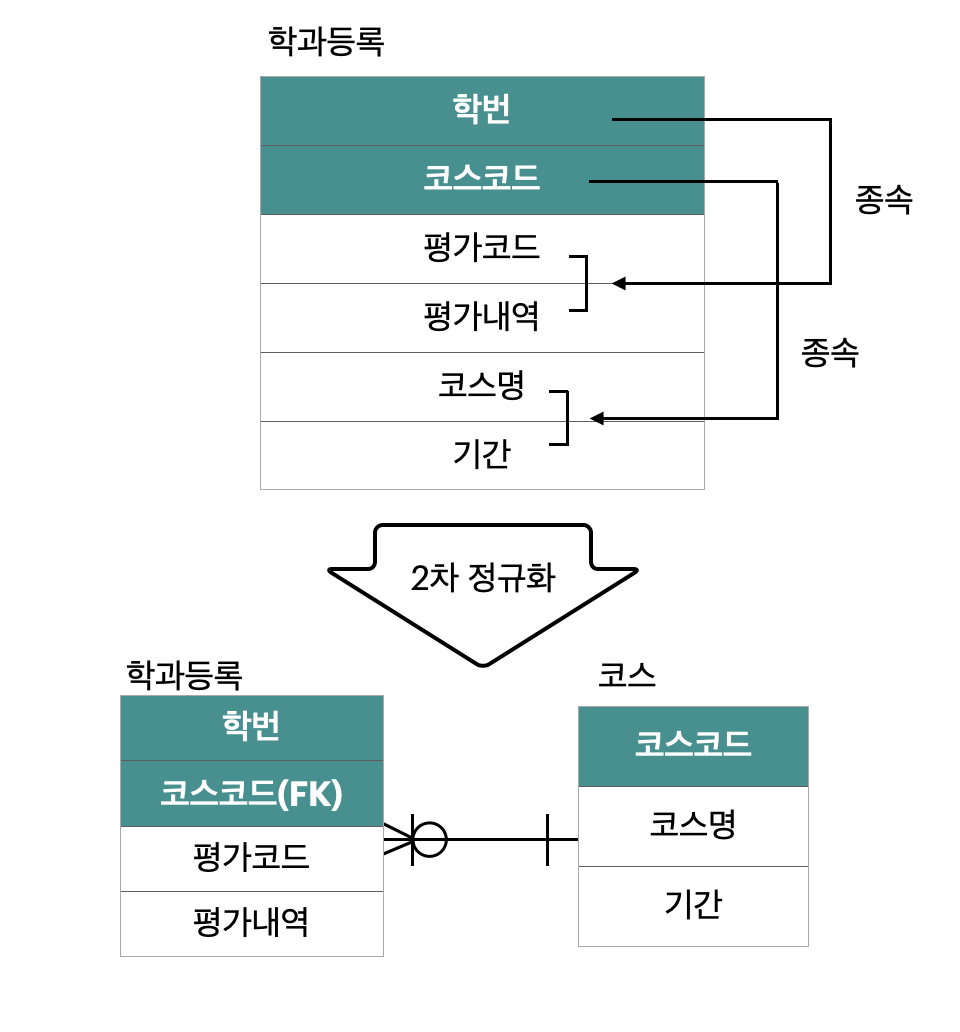
45번
ROLE
ROLE은 데이터베이스에서 OBJECT(테이블, 프로시저, 뷰) 등의 권한을 묶어서 관리할 수 있다.
49번
레코드
레코드 = 데이터가 들어가있는 행(ROW)
SQLD39_42 테이블의 COL1 은 {1, 1, 2, 3, 3} 이렇게 5개가 있습니다.COL1 을 하나씩 불러오면
문제 WHERE 조건이 A.COL1 = B.COL1 이므로A.COL1 = 1 일때 B.COL1 = 1 인 레코드 →2개
A.COL1 = 1 일때 B.COL1 = 1 인 레코드 →2개
A.COL1 = 2 일때 B.COL1 = 2 인 레코드 →1개
A.COL1 = 3 일때 B.COL1 = 3 인 레코드 →2개
A.COL1 = 3 일때 B.COL1 = 3 인 레코드 →2개
추천 강의자료
39회 상 : https://www.youtube.com/watch?v=SENIt9GFMV8
39회 하 : https://www.youtube.com/watch?v=9Kgmxr3PCsY&list=PLSiY9ClhS7WnWW6EfWlCz-P1Br3mGjFqw&index=4
연관 링크
- 기출 39회 26-50번 https://rise-up.tistory.com/775
- 기출 39회 1-25번 https://rise-up.tistory.com/774
- 기출 38회 1-50번 https://rise-up.tistory.com/764
- 기출 35회 31-50번 https://rise-up.tistory.com/763
- 기출 35회 1-30번 https://rise-up.tistory.com/762
- 기출 34회 30-50번 https://rise-up.tistory.com/761
- 기출 34회 1-29번 https://rise-up.tistory.com/760
- 기출 30회 1-24번 https://rise-up.tistory.com/759
- 기출 30회 25-50번 https://rise-up.tistory.com/758
자료 출처
https://yunamom.tistory.com/265
yurimac님 pdf 정리 자료
https://velog.io/@dongchyeon/오라클Oracle-그룹-함수-ROLLUP-CUBE-GROUPING-등
'SQL > SQLD 공부노트' 카테고리의 다른 글
| [SQL][SQLD] 기출 39회 1~25번 (1) | 2022.09.17 |
|---|---|
| [SQL][SQLD] 기출 38회 1~50번 (0) | 2022.09.14 |
| [SQL][SQLD] 기출 35회 31~50번 (0) | 2022.09.13 |
| [SQL][SQLD] 기출 35회 1~30번 (1) | 2022.09.13 |
| [SQL][SQLD] 기출 34회 30~50번 (0) | 2022.09.12 |