2번
성능 데이터 모델링 고려사항
- 정규화를 수행하여 데이터베이스 모델의 유연성을 확보
- 데이터베이스의 전체 용량, 월간, 연간 증감율을 예측 3)애플리케이션의 트랜잭션의 유형(CRUD: Create Read Update Delete)을 파악
- 합계 및 정산 등을 수행하는 반정규화 수행(성능향상을 위한 튜닝)
- 기본키와 외래키, 수퍼타입과 서브타입 등을 조정
- 성능관점에서 데이터 모델을 검증하고 확인
개념적 모델링
개체와 개체들 간의 관계에서 ER다이어그램을 만드는 과정
요구분석 단계에서 정의된 핵심 개체와 그들 간의 관계를 바탕으로 ERD를 생성하는 단계
- 사용자 관점에서 데이터 요구사항을 식별
논리적 모델링
ER다이어그램을 사용하여 관계 스키마 모델을 만드는 과정
개념 설계에서 추상화된 데이터를 구체화하여 개체, 속성을 테이블화하고 상세화 하는 과정
- M:N 관계해소, 식별자 확정, 정규화, 무결성 정의 등을 수행
물리적 모델링
관계 스키마 모델의 물리적 구조를 정의하고 구현하는 과정
논리적 설계 단계에서 표현된 데이터(ERD)를 실제 컴퓨터의 저장장치에 어떻게 표현할 것인가 (관계형 데이터베이스로 전환)
- 데이터가 물리적으로 저장되는 방법을 정의하는 것
5번
릴레이션(관계)
DB에서 정보를 구분하여 저장하는 기본 단위
DB테이블
ERD에서 네모칸 하나가 릴레이션임
11번
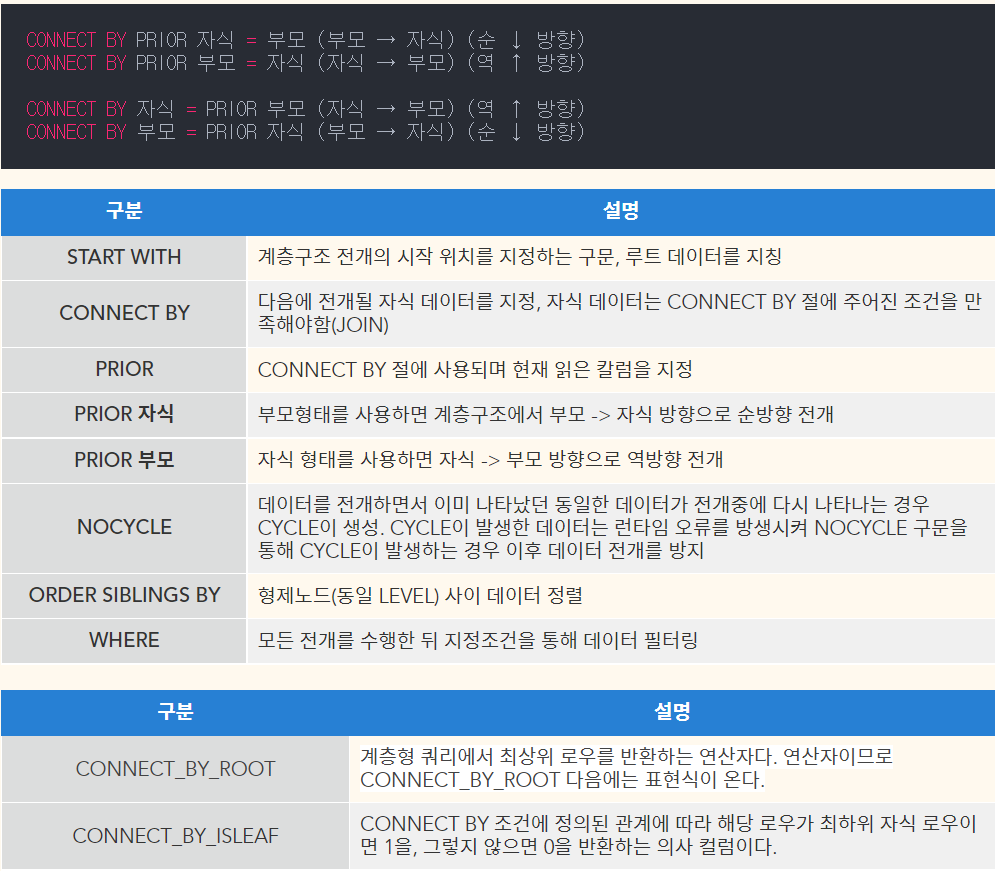
계층형 쿼리
PRIOR


12번
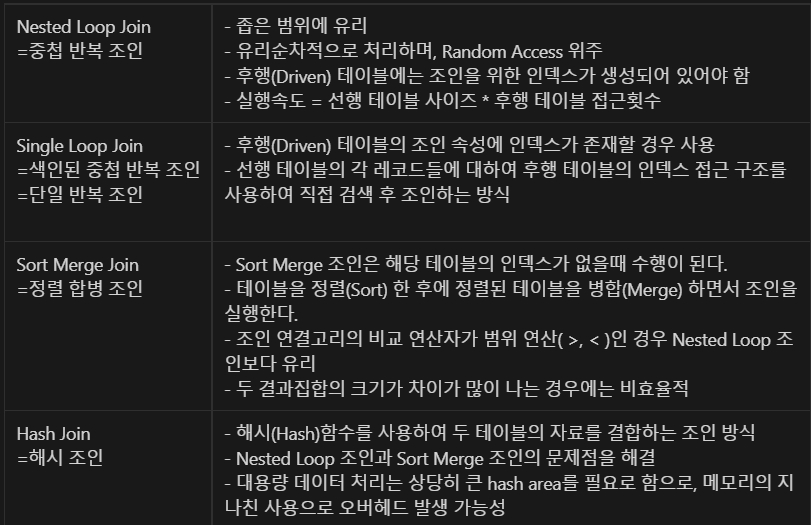
JOIN 설명
Nested Loop Join : 랜덤 엑세스 (Random Access) 발생 → 시스템 부하有
Sort Merge Join : 정렬을 유발하여 조인하는 형태를 사용
Hash Join : 정렬작업이 없어 정렬이 부담되는 대량배치작업에 유리
14번
DDL DML DCL TCL
DDL(데이터 정의어)
CREATE, DROP, MODIFY(오라클), ALTER(SQL서버), RENAME, TRUNCATE
DML(데이터 조작어)
SELECT, INSERT, DELETE, UPDATE
DCL(데이터 제어어)
GRANT, REVOKE
TCL(트랜잭션 제어어)
COMMIT, ROLLBACK, SAVE POINT
15번
NULL 카운트 YES or NO
대신 count(*) / count(1) 과 count(name) 은 다르다.
NULL 값을 포함하냐 마냐의 차이가 있다.
count(*) 과 count(1) 은 NULL 값인 컬럼도 포함하지만,
count(name) 은 NULL 값인 컬럼은 포함하지 않는다.
그룹바이 밴 1,2,3 하나씩으로 축약됨
1은 조조 하나라 1
2는 여포,유비니까 2
3은 관우 하니니까 1
17번
IN
IN() 연산자 : 안에 NULL이 있어도 비교연산 수행X
18번
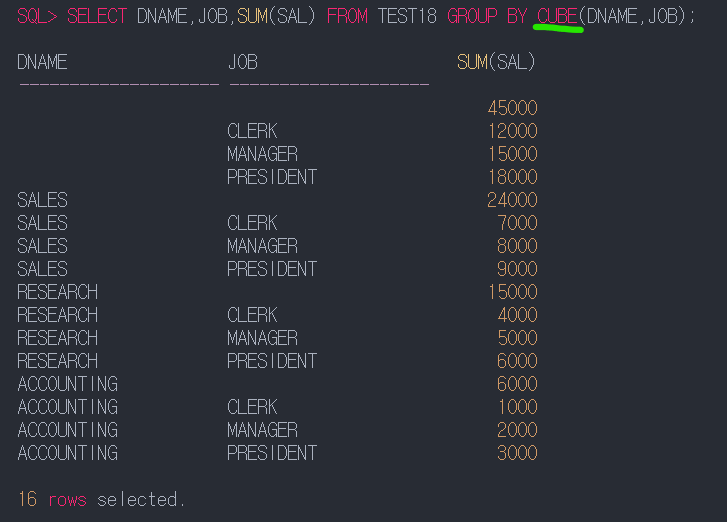
ROLLUP & CUBE & GROUPING SETS
1)ROLLUP

2)CUBE
3)GROUPING SETS

21번
SUM(급여) OVER() : 전체 급여의 합계
AVG(급여) OVER() : 평균 급여
UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING →시작부터 끝까지의 전체 합계
UNBOUNDED PRECEDING AND CURRENT ROW →누적 합계
OVER절
누적, 순위, 퍼센트, 평균, 총합 등 데이터를통계 or 집계 를 만들어주는 절
단일함수와 집계함수가 같이 올 수 없기 때문에, 서브쿼리를 사용하는 경우가 많은데요다수의 집계결과가 필요할 때 여러 서브쿼리와 그룹바이로 인해 복잡한 쿼리를 OVER 절을 사용하면 간단하게 작성할수있습니다.
※ SQL Server의 경우
집계 함수는 OVER 절 내의 ORDER BY 구문을 지원X
27번
ANY
다수의 비교값 중 하나라도 만족하면 TRUE
<>(같지않은),
28번
인덱스(INDEX)
인덱스에 대해서 연산을 하면 인덱스가 변형이 되므로 인덱스를 사용할수가 없다.
CREATE [UNIQUE] INDEX [스키마명.]인덱스명
ON [스키마명.]테이블명 (컬럼1 [, 컬럼2, 컬럼3, ...])
30번
실행계획(Execution Plan)
실행계획이란 SQL을 실행하기 위한 절차와 방법을 의미
- SQL개발자가 SQL을 작성하여 실행할 때, SQL을 어떻게 실행할 것인지를 계획하게 된다. 즉, SQL실행계획을 수립후 SQL을 실행
- 옵티마이저는 SQL의 실행계획을 수립하고 SQL을 실행하는 데이터베이스 관리 시스템의 소프트웨어
43번
순수 관계 연산자
관계형 데이터베이스에 적용할 수 있도록 개발한 관계 연산자
(DELETE 포함X)

46번
ROLLUP == GROUPING SETS
롤업과 같은 그루핑셋 코드
GROUP BY ROLLUP(COL1, COL2)
GOURP BY GROUPING SETS(COL1, COL2),(COL1),()
일정부분만 세면 합계 1000,2000,3000
해당 컬럼 다 합하면 소계 6000

※ 서브쿼리 위치에 따른 이름 및 반환형태
SQL 서브쿼리 SELECT, FROM, WHERE
- SELECT 절 서브쿼리 : 스칼라 서브쿼리
- FROM 절 서브쿼리 : 인라인뷰 서브쿼리
- WHERE 절 서브쿼리 : 중첩 서브쿼리
50번
CROSS JOIN
CROSS JOIN의 결과 개수는 두 테이블의 행의 개수를 곱한 개수가 된다.
CROSS JOIN
상호 조인이라고도 불리며,
한 쪽 테이블의 모든 행들과 다른 테이블의 모든 행을 조인시키는 기능
이러한 CROSS JOIN을 카테시안 곱 (Cartesian Product)라고도 한다
연관 링크
- 기출 39회 26-50번 https://rise-up.tistory.com/775
- 기출 39회 1-25번 https://rise-up.tistory.com/774
- 기출 38회 1-50번 https://rise-up.tistory.com/764
- 기출 35회 31-50번 https://rise-up.tistory.com/763
- 기출 35회 1-30번 https://rise-up.tistory.com/762
- 기출 34회 30-50번 https://rise-up.tistory.com/761
- 기출 34회 1-29번 https://rise-up.tistory.com/760
- 기출 30회 1-24번 https://rise-up.tistory.com/759
- 기출 30회 25-50번 https://rise-up.tistory.com/758
자료 출처
[SQLD] 38회 기출 문제 ( 50문제 / 정답 ) + 해설추가 (tistory.com)
yurimac님 pdf 정리 자료
유투버 곰사원님 pdf 정리 자료
https://mjn5027.tistory.com/51
'SQL > SQLD 공부노트' 카테고리의 다른 글
| [SQL][SQLD] 기출 39회 26~50번 (0) | 2022.09.18 |
|---|---|
| [SQL][SQLD] 기출 39회 1~25번 (1) | 2022.09.17 |
| [SQL][SQLD] 기출 35회 31~50번 (0) | 2022.09.13 |
| [SQL][SQLD] 기출 35회 1~30번 (1) | 2022.09.13 |
| [SQL][SQLD] 기출 34회 30~50번 (0) | 2022.09.12 |