1-9번
SELECT 1의미
해당 테이블이 가지고 있는 조건을 만족하는 개수의 행만큼 출력
릴레이션(관계)
DB에서 정보를 구분하여 저장하는 기본 단위
DB테이블
ERD에서 네모칸 하나가 릴레이션임
식별자 분류
- 대표성여부 → 주, 보조
- 스스로 생성여부 : 내부, 외부
- 속성의 수 : 단일, 복합
- 대체여부 : 본질,인조
ERD 작성순서
- 엔터티 그림
- 엔터티 배치
- 엔터티 관계설정
- 관계명 기술
- 관계의 참여도 기술
- 관계필수여부 기술
10번
비즈니스 프로세스에 의하여 만들어지는 식별자로 대체여부로 분리되는 식별자
→ 주식별자
식별자 분류
1.대표성여부 분류
주식별자, 보조식별자
- 주식별자 : 엔터티 내에서 각 어커런스를 구분할 수 있는 구분자, 타 엔터티와 참조관계를 연결O
- 보조식별자 : 구분자이나 대표성X, 참조관계 연결X
2.스스로생성여부
내부식별자, 외부식별자
- 내부 : 스스로 생성되는 식별자
- 외부 : 타 엔터티로부터 받아오는 식별자
3.속성의 수
단일식별자, 복합식별자
- 단일 : 하나의 속성으로 구성
- 복합 : 2개 이상의 속성으로 구성
4.대체 여부
본질식별자, 인조식별자
- 본질 : 업무에 의해 만들어지는 식별자
- 인조 : 인위적으로 만든 식별자
※ 주식별자 도출기준
- 해당 업무에서 자주 이용되는 속성임
- 명칭, 내역 등과 같이 이름으로 기술되는 것들은 X
- 복합으로 주식별자로 구성할 경우 너무 많은 속성X -> 너무 많으면 인조식별자 생성한다.
12번
COALESCE()
NULL 값이 아닌 첫번째 값을 반환
행(row)으로 진행
SELECT COALESCE(COL1,COL2*50,50) FROM SQLD_39_12COL1 을 기준 ( 100, 3000, 50)COL1(100) → 100COL1(NULL) → COL2(60) * 50 →3000COL1(NULL) → COL2 = NULL 이므로 → 50
13번
INDEX 생성
CREATE index [인덱스이름] on [테이블이름] (컬럼명);
ex)
CREATE index indmember on T_MEMBER(kind);
14번
9-3인데 MINUS는 중복제거하므로 3 3두개인게 3하나만 가게되므로 5가 됨
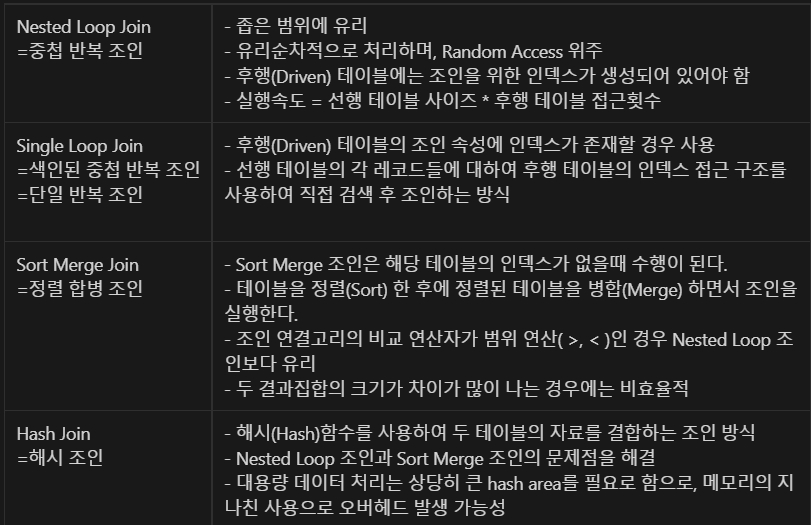
15번
SORT MERGE JOIN
조인되는 N개의 테이블을 모두 정렬한 후에 조인을 수행
해당 테이블의 인덱스가 없을때 수행
병렬구조로 정렬함
각 데이터에 대하여 sort(정렬)를 병렬로 1,2번을 진행하고 후에 merge해서 합침

16번
LPAD 사용 이유
트리 구조에서 정렬 시에, 공백으로 계층구조 분류를 잘 보이기 위함

17번
순위함수
- RANK 함수는 동일순위 처리가 가능하다.
- DENSE_RANK 함수는 RANK 함수와 같은 역할을 하지만 동일 등수 순위에 영향이 없다.
- ROW_NUMBER 함수는 특정 동일 순위가 부여되지 않는다
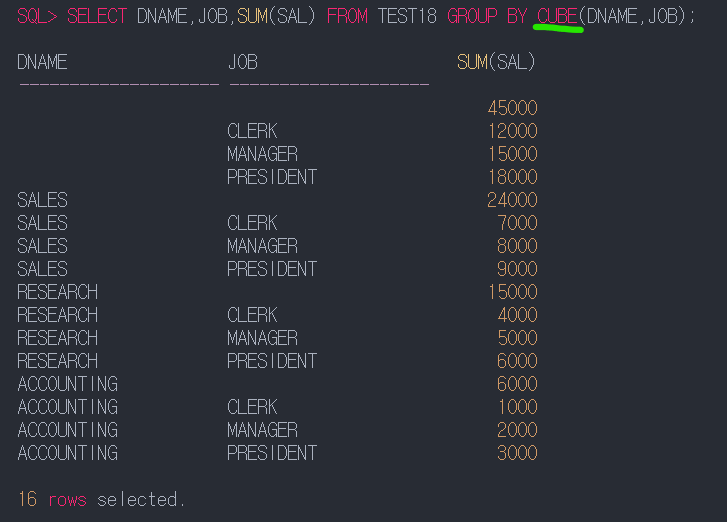
18번
GROUPING SETS 함수
원하는 부분의 소계만 손쉽게 추출하여 계산할 수 있는 함수


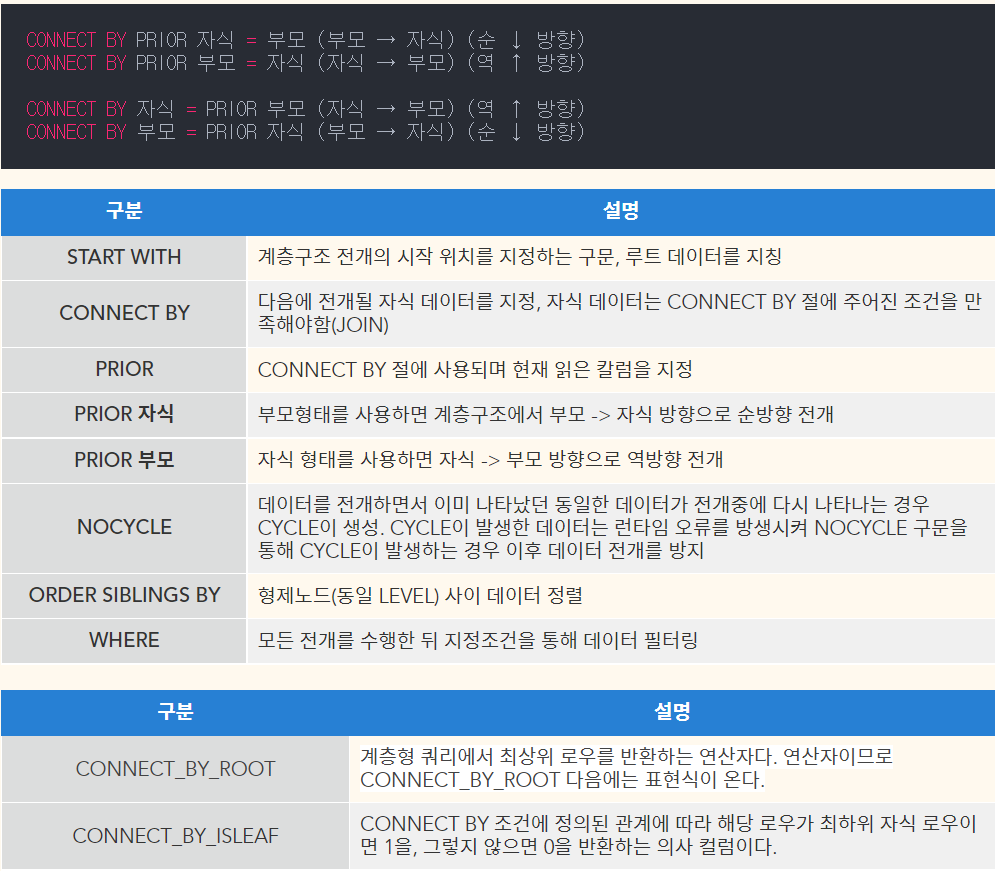
21번
ORDER SIBLINGS BY
ORDER SIBLINGS BY 를 수행하면 전체 테이블이 아니라 계층형으로 된 데이터값(특정 칼럼) 기준으로 정렬된다.
(1) NOT IN (3) 이므로 3이 포함되면 전개를 멈춤
(2) CONNECT BY PRIOR ID = PARENT_ID (부모 ID 를 기준으로 자식 ID 를 검색) 순반향
(3) NO CYCLE 옵션을 사용할 수 있다.

22번
INDEX RANGE SCAN
최대값을 쉽게 검색 가능
24번
문자의 길이 : CHAR vs VARCHAR
CHAR는 길이가 서로 다르면, 짧은 쪽에 공백(space)를 추가하여 같은 값으로 판단한다.
VARCHAR(가변길이 문자형 : 입력한 크기만큼 할당 )는 같은 값에서 길이만 서로 다를 경우, 다른 값으로 판단함
예) CHAR(5)으로 칼럼을 생성하고 입력값이 3개의 문자일때 'abc' → 'abc ' 와 같은식으로 나머지 2개는 공백으로 입력된다.
문자형과 숫자형을 비교 시 문자형을 숫자형으로 묵시적 변환하여 비교
연산자 실행 순서는 괄호, NOT, 비교연산자, AND, OR순
추천 강의자료
39회 상 : https://www.youtube.com/watch?v=SENIt9GFMV8
39회 하 : https://www.youtube.com/watch?v=9Kgmxr3PCsY&list=PLSiY9ClhS7WnWW6EfWlCz-P1Br3mGjFqw&index=4
연관 링크
- 기출 39회 26-50번 https://rise-up.tistory.com/775
- 기출 39회 1-25번 https://rise-up.tistory.com/774
- 기출 38회 1-50번 https://rise-up.tistory.com/764
- 기출 35회 31-50번 https://rise-up.tistory.com/763
- 기출 35회 1-30번 https://rise-up.tistory.com/762
- 기출 34회 30-50번 https://rise-up.tistory.com/761
- 기출 34회 1-29번 https://rise-up.tistory.com/760
- 기출 30회 1-24번 https://rise-up.tistory.com/759
- 기출 30회 25-50번 https://rise-up.tistory.com/758
자료 출처
https://yunamom.tistory.com/265
yurimac님 pdf 정리 자료
https://velog.io/@dongchyeon/오라클Oracle-그룹-함수-ROLLUP-CUBE-GROUPING-등
'SQL > SQLD 공부노트' 카테고리의 다른 글
| [SQL][SQLD] 기출 39회 26~50번 (0) | 2022.09.18 |
|---|---|
| [SQL][SQLD] 기출 38회 1~50번 (0) | 2022.09.14 |
| [SQL][SQLD] 기출 35회 31~50번 (0) | 2022.09.13 |
| [SQL][SQLD] 기출 35회 1~30번 (1) | 2022.09.13 |
| [SQL][SQLD] 기출 34회 30~50번 (0) | 2022.09.12 |