<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
1. 최상위 태그 <mapper>
namespace속성
마이바티스 설정파일(config.xml)에 등록한 매퍼파일의 값을 넣는 속성(element)
자바에서 어느 매퍼를 쓸지 알 수 있게 해주는 역할
<mapper namespace="memberMapper">
</mapper>
2. 쿼리문 태그 : <select>,<insert>,<update>,<delete>
이후로 나오는 태그들은 sql에서 썼던 CRUD의 명령어들이 태그화 된 것이므로 그대로 쓰면 되고,
속성(element)만 추가하면 된다
<mapper namespace="memberMapper">
<select id="loginMember" parameterType="member.model.vo.Member" >
쿼리문 내용
ex)
SELECT *
FROM MEMBER
WHERE USER_ID = #{userId} AND USER_PWD = #{userPwd}
</select>
</mapper>
1)id : 쿼리문의 고유 아이디(유일한 구분자) - mapper태그 안에 쿼리가 엄청 여러개이기 때문에 각각을 구분할 pk역할을 하는 id속성이 필요 2)parameterType : 클래스의 풀네임 또는 (설정되었다면)별칭 3)resultType : 반환받을 데이터의 데이터타입 지정 - 쿼리 실행 후 나온 결과(ex:ResulSet) 옮겨 담을 객체를 정해주는 것
3.<resultMap>
vo클래스 필드명(담을 객체의 필드명)과 sql컬럼명 매핑시켜주는 태그
resultMap태그 속성값
1) type : 클래스 풀네임or별칭 2) id : pk역할. 이 resultMap이 어느 resultMap맵인지 식별용
<resultMap type="Member" id="memberResultSet">
resultMap 하위 태그
1)id태그 : pk역할(기본키) 하는 얘가 들어감. - column : DB의 컬럼명 - property : 매핑 시킬 자바 vo의 필드명 2)result태그 : 일반 컬럼이 들어감
방법1
SELECT EMP_ID,EMP_NAME,SALARY FROM EMPLOYEE;
방법2
SELECT EMP_ID,EMP_NAME, SALARY
FROM EMPLOYEE;
SELECT 컬럼명 -- 조회하고자 하는 컬럼명 기술 FROM 테이블명 -- 조회하고자 하는 컬림이 포함된 테이블명 기술 WHERE 조건식; -- 행을 선택하는 조건 기술, 조건을 만족하는 행만 반환 -- 조건식 복수로 붙여서 사용가능. 복수라도 WHERE절 한개만 기술
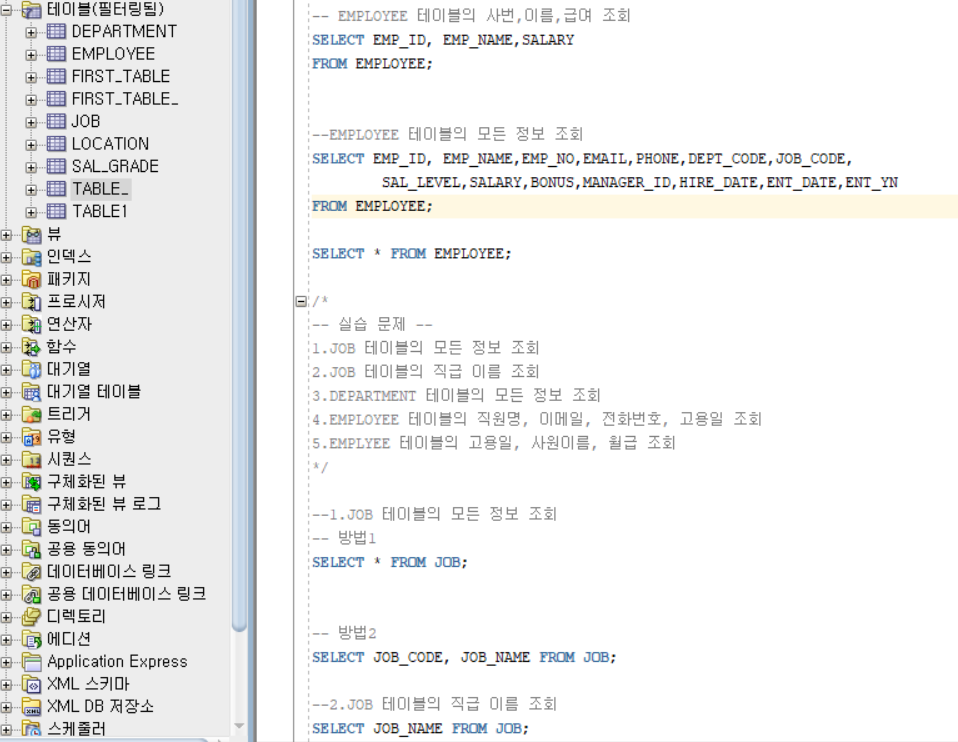
한 테이블의 모든 정보 조회
--EMPLOYEE 테이블의 모든 정보 조회
방법1
SELECT EMP_ID,EMP_NAME, EMP_NO, EMAIL, PHONE, DEPT_CODE, JOB_CODE, SAL_LEVEL, SALARY,
BONUS, MANAGER_ID, HIRE_DATE, ENT_DATE, ENT_YN FROM EMPLOYEE ;
방법2
SELECT * -- * : 전체
FROM EMPLOYEE;
DISTINCT
중복제거
DISTINCT는 한번만 쓸 수 있다
-- DISTINCT : 중복제거
SELECT DISTINCT JOB_CODE
FROM EMPLOYEE;
-- EMPLOYEE 테이블에서 직원의 부서 코드를 중복 없이 조회
SELECT DISTINCT DEPT_CODE
FROM EMPLOYEE;
-- DISTINCT는 한번만 쓸 수 있다
--SELECT DISTINCT DEPT_CODE, DISTINCT DEPT_CODE -- ERROR
--FROM EMPLOYEE;
DISTINCT A,B 콤마로 같이 쓰면 ()로 묶은 효과 발생
콤마로 두 컬럼을 묶으면 두 컬럼의 조건이
AND조건으로 교집합 된 것만 중복 제거한다
SELECT DISTINCT DEPT_CODE, JOB_CODE -- 콤마로 두 컬럼을 묶으면 두 컬럼의 조건이
FROM EMPLOYEE; -- AND조건으로 교집합 된 것만 중복 제거한다
리터럴(literal)
값 자체
싱글쿼테이션( ' ' )
오라클에서는 문자,문자열,데이트 상관없이 다 싱글쿼테이션(’ ‘)으로 감싸준다
컬럼 별칭
컬럼명 AS 별칭 / 컬럼명 AS “별칭” / 컬럼명 별칭 / 컬럼명 “별칭”
별칭 : ""
쌍따옴표( “”)를 무조건 붙여야하는 조건
1)별칭에 특수문자가 들어갈 경우 2)별칭이 숫자로 시작할 경우 쌍따옴표 = 더블 쿼테이션(” ”) EX) 직원 명 ←띄어쓰기 공백 특수문자라 “직원 명”으로 적어줘야한다 EX) SALARY*12 AS 연봉
SELECT 컬럼명 -- 조회하고자 하는 컬럼명 기술 FROM 테이블명 -- 조회하고자 하는 컬림이 포함된 테이블명 기술 WHERE 조건식; -- 행을 선택하는 조건 기술, 조건을 만족하는 행만 반환 -- 조건식 복수로 붙여서 사용가능. 복수라도 WHERE절 한개만 기술
비교연산자
>, <, >=, <=, = ,!=
크다, 작다, 크거나 같다 같다 : = 같지않다 : != , ^= , <>
컬럼 별칭
컬럼명 AS 별칭 / 컬럼명 AS “별칭” / 컬럼명 별칭 / 컬럼명 “별칭”
별칭 : ""
리터럴(literal)
값 자체
싱글쿼테이션( ' ' )
오라클에서는 문자,문자열,데이트 상관없이 다 싱글쿼테이션(’ ‘)으로 감싸준다
-- 컬럼 별칭
-- 컬럼명 AS 별칭 / 컬럼명 AS “별칭” / 컬럼명 별칭 / 컬럼명 “별칭”
/*
리터럴(literal)
값 자체 ‘ ‘
오라클에서는 문자,문자열,데이트 상관없이 다 싱글쿼테이션(’ ‘)으로 감싸준다
데이터 타입에 상관없이 별칭(””) 외에는 다 싱글쿼테이션으로 감싼다
*/
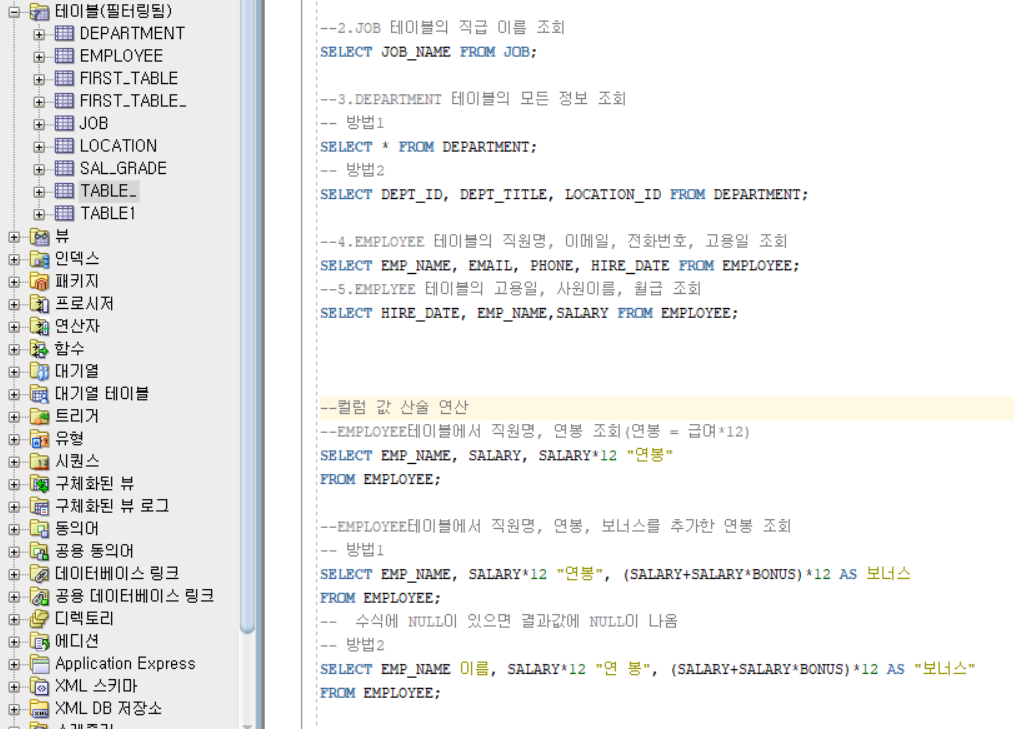
-- EMPLOYEE 테이블에서 직원의 직원 번호, 사원명, 급여, 단위 조회
SELECT EMP_NO, EMP_NAME, SALARY, '원' "단위 : 원"
FROM EMPLOYEE;
SELECT EMP_NO, EMP_NAME, SALARY, '@' "원"
FROM EMPLOYEE;
-- 별칭 : ""
-- 리터럴을 싱글쿼테이션으로 처리한다 : ' '
-- '원'이라는 컬럼을 보여주고 싶지않으면 더블쿼테이션""으로 단위써주자
-- EMPLOYEE테이블에서 직원의 직급 코드 조회
SELECT EMP_ID, '직급코드' AS 직급코드
FROM EMPLOYEE;
SELECT EMP_NAME, EMAIL
FROM EMPLOYEE
WHERE EMAIL LIKE 'b%';
-- 결과 : 방명수 bang ns@kh.kr
-- 결과 : 없음
-- 리터럴은 대소문자 철저히 구별하기에 대문자 BANG으로 시작하는 EMAIL이 없어서 안나온 것
-- EMPLOYEE 테이블에서 직원의 부서 코드를 중복 없이 조회
SELECT DISTINCT JOB_CODE
FROM EMPLOYEE;
-- DISTINCT는 한번만 쓸 수 있다
--SELECT DISTINCT DEPT_CODE, DISTINCT DEPT_CODE -- error
--FROM EMPLOYEE;
SELECT DISTINCT DEPT_CODE, JOB_CODE -- 콤마로 두 컬럼을 묶으면 두 컬럼의 조건이
FROM EMPLOYEE; -- AND조건으로 교집합 된 것만 중복 제거한다
/*
SELECT 컬럼명 -- 조회하고자 하는 컬럼명 기술
FROM 테이블명 -- 조회하고자 하는 컬림이 포함된 테이블명 기술
WHERE 조건식; -- 행을 선택하는 조건 기술, 조건을 만족하는 행만 반환
-- 조건식 복수로 붙여서 사용가능. 복수라도 WHERE절 한개만 기술
--비교연산자
>, <, >=, <=, = ,!=
크다, 작다, 크거나 같다
같다 : =
같지않다 : != , ^= , <>
*/
--EMPLOYEE테이블에서 부서코드가 'D9'인 직원의 이름, 부서코드 조회
SELECT EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';
-- '' 없이 D9만 쓰면 컬럼으로 인지하게 됨
-- 'd9'라고 써도 안됨. 리터럴은 대소문자 구분
--급여가 4000000이상인 직원의 이름, 급여 조회
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY >= 4000000;
-- EMPLOYEE테이블에서 부서코드가 D9이 아닌 사원의 사번, 이름, 부서코드조회
SELECT EMP_NO, EMP_NAME, DEPT_CODE
FROM EMPLOYEE
--WHERE DEPT_CODE != 'D9';
WHERE DEPT_CODE <> 'D9';
WHERE DEPT_CODE ^= 'D9';
-- EMPLOYEE 테이블에서 퇴사 여부가 N인 직원을 조회하고 근무 여부를 재직중으로 표시
-- 사번,이름, 고용일, 근무여부 조회
SELECT EMP_ID, EMP_NAME, HIRE_DATE, '재직중' "근무여부"
FROM EMPLOYEE
WHERE ENT_YN = 'N';